The introduction of retrieval augmented generation (RAG) represents a significant leap forward. This innovative approach is not just a technological advancement; it's a paradigm shift in how AI systems process, understand, and generate human language. This blog post delves into the intricacies of RAG and its architecture, exploring how it's transforming the landscape of AI.
What is retrieval augmented generation (RAG)?
Retrieval augmented generation is a technique that blends the generative capabilities of large language models (LLMs) like GPT with the precision of external knowledge retrieval. Traditional LLMs, impressive as they are, have limitations. They often generate responses based on patterns learned during training, which can result in outdated or generalized information. RAG addresses these limitations by incorporating real-time data retrieval into the response generation process, ensuring more accurate, relevant, and context-specific outputs.
The Need for RAG in Today's AI Landscape
In a world where data is continuously evolving, the static nature of pre-trained models poses a challenge. These models, once trained, do not automatically update with new information.
As a result, they can become outdated, losing relevance in rapidly changing scenarios. RAG architecture intervenes here by connecting the model to an up-to-date external knowledge source, allowing it to fetch and integrate the latest information into its responses.
The Architecture of RAG: A Deep Dive
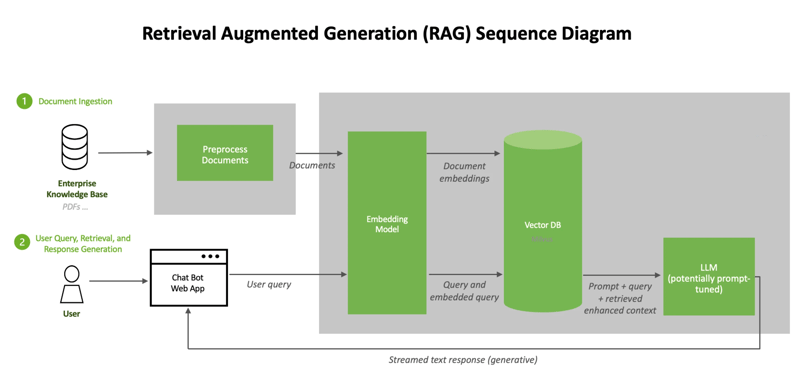
The architecture of RAG is a fascinating blend of several AI components, each playing a crucial role in delivering precise and current information. Let's break down its key elements:
- Large Language Model (LLM)
At the heart of RAG is a large language model like GPT. This model is responsible for understanding the context of a query and generating a base response. The LLM is trained on a vast corpus of text, enabling it to grasp a wide range of topics and language nuances.
- External Knowledge Database
RAG is connected to an external, continuously updated knowledge database. This database can be a collection of various sources such as websites, scientific journals, news articles, and more. The ability to access current and diverse data sources is what sets RAG apart from traditional LLMs.
- Embedding Model
The embedding model is a critical bridge between the LLM and the external database. It converts the query and the contents of the database into vector representations (embeddings). These embeddings allow the system to measure the similarity between the query and the available information in the database, facilitating accurate data retrieval.
- Retrieval Mechanism
This mechanism uses the embeddings to retrieve the most relevant pieces of information from the external database. It selects data that closely matches the context and intent of the query, ensuring that the information integrated into the response is pertinent.
Integration and Response Generation
Finally, the retrieved information is integrated into the response generation process. The LLM, armed with up-to-date external data, crafts a response that is both contextually relevant and informationally rich.
Benefits and Applications of RAG
RAG's ability to augment generative models with real-time data has vast implications. Some of the key benefits include:
- Enhanced Accuracy and Relevance: By accessing the latest information, RAG-generated responses are more accurate and relevant to current events and developments.
- Customization and Flexibility: RAG can be tailored to specific domains by connecting to specialized databases, making it ideal for industries like healthcare, finance, and legal.
- Reducing Information Overload: RAG can distill vast amounts of data into concise, relevant answers, aiding in decision-making processes.
In practical terms, RAG can be employed in various applications such as AI chatbots, virtual assistants, research tools, and content creation aids. Its versatility makes it a valuable asset across multiple sectors.
Challenges and Future Directions
While RAG is transformative, it's not without challenges. Ensuring the reliability and accuracy of the external data sources is crucial. There's also the need to continuously refine the integration process to maintain coherence and contextuality in responses. Looking ahead, the development of more sophisticated embedding models and retrieval mechanisms will further enhance RAG's capabilities.
Conclusion
Retrieval Augmented Generation represents a significant advancement in the field of AI. By bridging the gap between static pre-training and dynamic real-world data, RAG paves the way for more intelligent, adaptable, and useful AI systems. As we continue to push the boundaries of what AI can achieve, RAG stands as a testament to the innovative spirit driving the field forward.
Dropchat's Use of RAG in Chatbot Development
Dropchat harnesses the power of RAG to create sophisticated AI-powered chatbots that are not only knowledgeable but also highly adaptable to the ever-changing landscape of data. These chatbots excel in delivering accurate, up-to-date information, making them invaluable assets in customer service, data retrieval, and interactive communication. By integrating RAG, Dropchat ensures that its chatbots are not just answering questions but are providing informed, context-aware responses that enhance user experience. Interested in experiencing this cutting-edge technology firsthand.
Click below to sign up for a trial or demo of Dropchat's innovative chatbot solutions and witness the transformative impact of RAG in real-time communication.
